The Abolitionist Project as Conceived By ChatGPT-4
페이지 정보

본문
You can also enter a listing of ideas into chatgpt en español gratis and ask it to improve or adapt them. They are often quite artistic, developing with new concepts or producing content that seems as if a human may have made it. With the assistance of RLHF (Reinforcement Learning with Human Feedback), we explored the importance of human suggestions and its huge affect on the efficiency of general-function chatbots like ChatGPT. In this chapter, we explained how machine learning empowers ChatGPT’s outstanding capabilities. We also understood how the machine studying paradigms (Supervised, Unsupervised, and Reinforcement learning) contribute to shaping ChatGPT’s capabilities. Now, imagine making these instruments even smarter by using a way known as reinforcement learning. Desai also considers AI tools as a resource for basic information that college students can access off hours. Large language models (LLMs) are like super-good instruments that derive data from huge quantities of textual content. That’s why major firms like OpenAI, Meta, Google, Amazon Web Services, IBM, DeepMind, Anthropic, and more have added RLHF to their Large Language Models (LLMs). While there’s nonetheless every day information about numerous services and companies integrating the GPT API into their merchandise, the thrill round it has quieted.
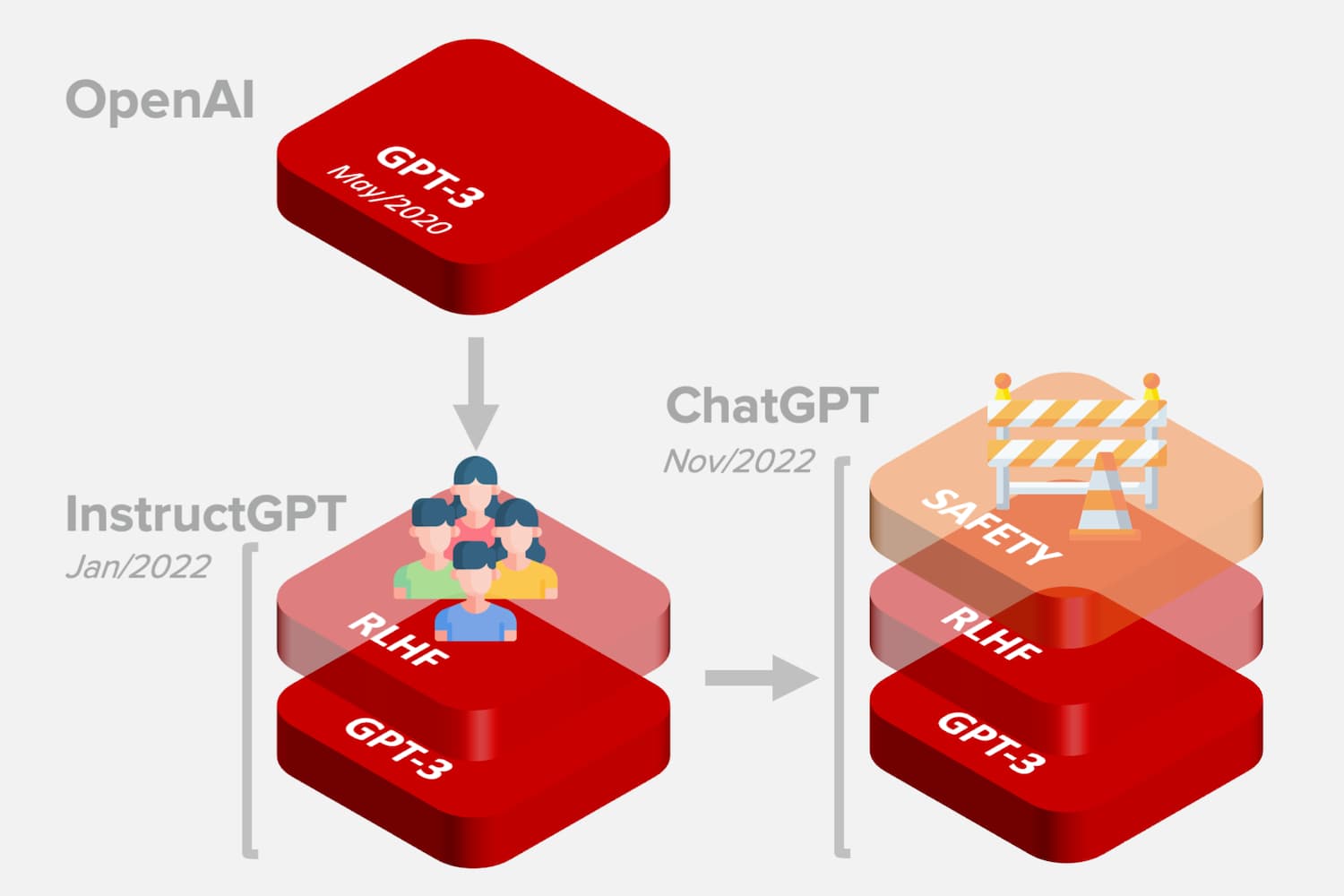 They acknowledge patterns that deviate from regular conduct to alert companies of fraud. Generative Models signify a class of algorithms that be taught patterns from present data to generate novel content material. For ChatGPT, OpenAI adopted an identical strategy to InstructGPT models, with a minor difference in the setup for information assortment. Bias: Like other AI fashions, ChatGPT can inherit biases present in its coaching data. On this chapter, we are going to know Generative AI and its key components like Generative Models, Generative Adversarial Networks (GANs), Transformers, and Autoencoders. Let’s explore some of the important thing elements inside Generative AI. In reality, RLHF has develop into a key constructing block of the preferred LLM-ChatGPT. In this section, we are going to clarify how ChatGPT used RLHF to align to the human feedback. As we can see within the picture, the suggestions cycle is between the agent’s understanding of the objective, human feedback, and the reinforcement studying coaching. RLHF works by involving small increments of human suggestions to refine the agent’s learning process. In comparison with supervised learning, reinforcement studying (RL) is a sort of machine studying paradigm where an agent learns to make decisions by interacting with an atmosphere. In such situations human suggestions turns into essential and can make a huge effect.
They acknowledge patterns that deviate from regular conduct to alert companies of fraud. Generative Models signify a class of algorithms that be taught patterns from present data to generate novel content material. For ChatGPT, OpenAI adopted an identical strategy to InstructGPT models, with a minor difference in the setup for information assortment. Bias: Like other AI fashions, ChatGPT can inherit biases present in its coaching data. On this chapter, we are going to know Generative AI and its key components like Generative Models, Generative Adversarial Networks (GANs), Transformers, and Autoencoders. Let’s explore some of the important thing elements inside Generative AI. In reality, RLHF has develop into a key constructing block of the preferred LLM-ChatGPT. In this section, we are going to clarify how ChatGPT used RLHF to align to the human feedback. As we can see within the picture, the suggestions cycle is between the agent’s understanding of the objective, human feedback, and the reinforcement studying coaching. RLHF works by involving small increments of human suggestions to refine the agent’s learning process. In comparison with supervised learning, reinforcement studying (RL) is a sort of machine studying paradigm where an agent learns to make decisions by interacting with an atmosphere. In such situations human suggestions turns into essential and can make a huge effect.
 This intellectual mixture is the magic behind one thing referred to as Reinforcement Learning with Human Feedback (RLHF), making these language models even better at understanding and responding to us. In addition to increasingly complex questions about whether or not ChatGPT is a research instrument or a plagiarism engine, there’s also the likelihood that it can be utilized for learning. We're particularly eager about whether or not it will possibly serve as a common sentiment analyzer. Previous to this, the OpenAI API was pushed by GPT-three language model which tends to supply outputs which may be untruthful and toxic as a result of they are not aligned with their customers. Now, as a substitute of positive-tuning the unique gpt gratis-three model, the builders of a versatile chatbot like ChatGPT decided to make use of a pretrained mannequin from the GPT-3.5 sequence. In different words, the builders opted to superb-tune on prime of a "code mannequin" instead of purely text-based model. "Do you understand the code you’re pulling in, and in the context of your application, is it safe? Once you have examined your code and are happy with the outcomes, you can deploy your utility. This implies, with this new resource at their fingertips, cybersecurity professionals can shortly and simply access information, seek for answers, brainstorm ideas and take steps to detect and protect towards threats extra shortly.
This intellectual mixture is the magic behind one thing referred to as Reinforcement Learning with Human Feedback (RLHF), making these language models even better at understanding and responding to us. In addition to increasingly complex questions about whether or not ChatGPT is a research instrument or a plagiarism engine, there’s also the likelihood that it can be utilized for learning. We're particularly eager about whether or not it will possibly serve as a common sentiment analyzer. Previous to this, the OpenAI API was pushed by GPT-three language model which tends to supply outputs which may be untruthful and toxic as a result of they are not aligned with their customers. Now, as a substitute of positive-tuning the unique gpt gratis-three model, the builders of a versatile chatbot like ChatGPT decided to make use of a pretrained mannequin from the GPT-3.5 sequence. In different words, the builders opted to superb-tune on prime of a "code mannequin" instead of purely text-based model. "Do you understand the code you’re pulling in, and in the context of your application, is it safe? Once you have examined your code and are happy with the outcomes, you can deploy your utility. This implies, with this new resource at their fingertips, cybersecurity professionals can shortly and simply access information, seek for answers, brainstorm ideas and take steps to detect and protect towards threats extra shortly.
But when will serps simply give us the answer? CGPT: There are various duties that AI is already capable of performing, however as the know-how continues to advance, there are lots of more duties that AI will likely be ready to help with sooner or later. If I wish to satirize some company, I can remember again to some Chaplin and go, "Ah, there was an excellent technique." If I remember the visual techniques in an Akira Kurosawa film, I can attempt to render them in prose to see how they’d work, after which discard or improve them if they do. Now you know the way do AI chatbot work, let’s see chatgpt gratis. The brand new information set is now used to train our reward model (RM). This coverage now generates an output after which the RM calculates a reward from that output. This reward is then used to replace the coverage utilizing PPO. The first step mainly entails data collection to practice a supervised policy mannequin, identified as the SFT mannequin. On this step, a specific algorithm of reinforcement studying referred to as Proximal Policy Optimization (PPO) is utilized to tremendous tune the SFT mannequin allowing it to optimize the RM. Reinforcement learning acts as a navigational compass that guides ChatGPT through dynamic and evolving conversations.
When you have virtually any concerns about wherever along with the way to make use of chat gpt es gratis, it is possible to e mail us from the web-page.
- 이전글The Debate Over Chatgpt 4 25.01.26
- 다음글How one can Make Your Chatgpt 4 Look Superb In 5 Days 25.01.26
댓글목록
등록된 댓글이 없습니다.